■技術解説■ RAGを活用した生成AIの回答生成精度に直結する「Retriever」。Retrieverの仕組みと最適化戦略とは?


生成AI・LLMを活用し、企業の社内情報や特定情報から回答を生成するにあたって、LLMのハルシネーションを低減するRAG(Retrieval Augmented Generation:検索拡張生成)への関心が高まっています。最近では、多数のRAGソリューションの中から自社に適したものを探す企業が増えています。
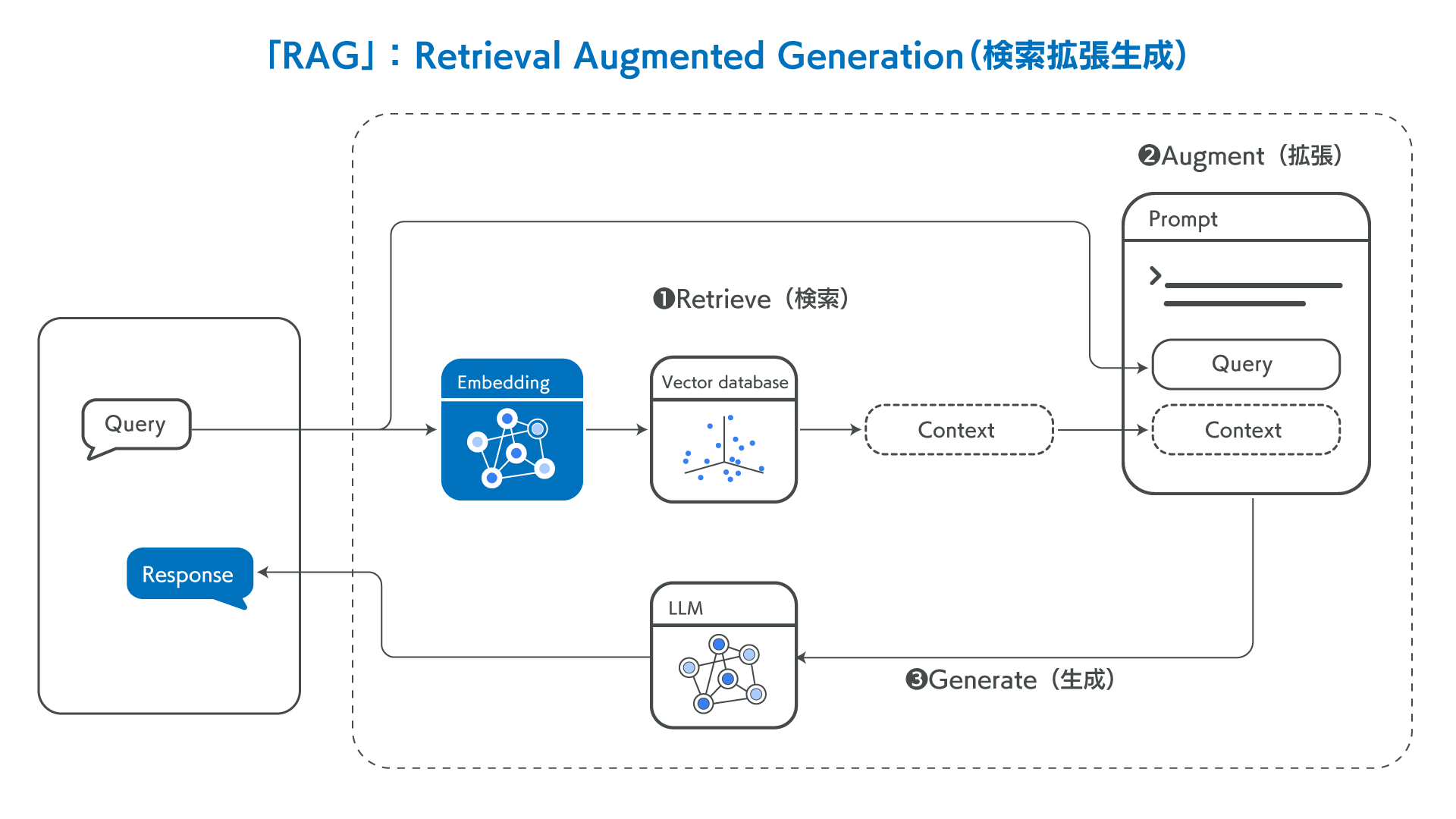
RAGの仕組みや企業向けのRAGにつきましては、以前の当ブログの記事でもご紹介しておりますので、よろしければ過去記事(技術解説:企業向けRAGとは?)もご覧ください。

RAGにおいて「Retriever」が重要である理由
以前の記事でも紹介しました通り、RAGでは ”質問の意図を踏まえた上でデータベースから検索し、関連性の高いドキュメントと該当箇所を特定すること” が非常に重要です。このRAGにおける検索の仕組みを「Retriever」(リトリーバー/レトリーバー、検索AI)と呼びます。
皆さんは、“Garbage In, Garbage Out”という言葉を聞いたことはありますか?これはAIモデル学習において良く使われる言葉で、ゴミ(= Garbage)を入れたらゴミが出てくる、つまり、品質の悪いデータで学習すると品質の悪いAIモデルができあがる、という意味です。
RAGにおいても、この “Garbage In, Garbage Out” が発生します。
RAGでは、質問に関連した正確な情報をコンテキストとして入力すると正確な回答が生成されますが、関連性のないコンテキストを入れるとハルシネーション、誤った回答が生成されてしまいます。
検索対象が10ページ程度の文書ひとつであれば、質問に関連する部分を見つけるのは簡単です。では、RAGの対象ドキュメントが多数あった場合、質問に関連するコンテキストをどのように正確に入力するのでしょうか?
例えば、ドキュメントが数十〜数百ページで構成され、さらにそのようなドキュメントが大量にあった場合、質問に関連する部分を見つけるのはなかなか困難です。特に、同じドメイン(業種や業務領域)のドキュメントであれば似ている場合も多く、質問に関連するコンテキストを特定するのがさらに難しくなります。
Allganize の RAGチーム では、回答生成精度へ大きな影響を与えるRetrieverの最適化に注力しています。
ここからは、Allganize がどのようにRAGの Retriever を設計しているのか、簡単にご紹介します。
テキストを適切なサイズに分割する「チャンク」
RAGの Retrieval の設計での最初の検討事項は、「チャンク」の分割単位です。
チャンクとは
ドキュメントに含まれるテキスト全体を一度に処理するのは難しいため、テキストを「チャンク」という小さな単位に分割して処理します。
チャンク分割方法は複数あり、一定の長さ(固定長)で分割する手法、文章で分割する手法、マークダウンなどの構造をもとに分割する手法など、さまざまなアプローチ方法があります。
チャンク方法でどのように回答生成結果に影響があるか、簡単な例で説明します。
たとえば、ドキュメントを300トークンでチャンキングしたとします。以下のような金融施策に関するドキュメントを事前に登録し、「新NISAの普及のための施策は?」という質問をしたとします。赤枠内に回答が記載されていますが、赤枠部分のトークンは300トークンを超えています。300トークンでチャンク分割してコンテキストを構成すると、周辺情報が失われてしまい、良い回答が得られない場合があります。

上記のようなケースが存在するため、Allganizeでは、さまざまなチャンク方式を試し、ドキュメントのページ単位で分割する方式を採用しています。どのような方法でも確実な正解があるわけではありませんが、内部的にテストを行った結果、ページ単位が最も良いパフォーマンスが得られたためです。ページ単位で分割することにより、質問に対する回答を広い範囲から提供できます。
質問に関連するチャンクをどのように見つけるのか?
多くのチャンクがある場合、どのように質問に関連するチャンクを見つけるのでしょうか。
(1)正確に一致する単語が多い場合は、キーワード検索
Allganize では、ChatGPTの登場以前から Retrieval への関心が高く、トライを重ねています。生成ベースのモデルの性能が向上する前から、抽出型の自然言語理解の手法によってユーザーの質問に対して精度高く回答を提供していました。
抽出型は生成型のように多様な形態の回答を提供できないという欠点がありますが、2023年以前は、生成型と比較して抽出型の方がパフォーマンスが優れていました。
抽出型も同様に、Retrievalを使用して質問に関連するチャンクを見つける必要があります。
Allganizeでは、抽出型ではBERTを用いて単語を中心に探索するキーワード検索を採用していました。チャンクから質問の回答となる部分の開始位置と終了位置を特定し、それを回答として提供します。Retriever の実装方法として、キーワードベースの検索にElasticsearchを使用し、アルゴリズムにはBM25を採用しました。この方法では、文章の長さに対して正確に一致する単語が多いほど、関連度のランク順位が上昇します。
イメージを掴んでいただくために、簡単な例を挙げて紹介します。
「apple computer」という文字が含まれている3つの文章に対して、関連度を算出してみます。サンプルの文章と算出方法は、以下の画像にまとめました。

上記のように、キーワードの出現頻度や元の文章の長さなどを考慮して算出します。
キーワード検索のメリットは、直観的な仕組みで実装が容易である点です。直観的であるということは、性能に関するデバッグも容易であることを意味します。例えば、特定のキーワードに対して重み付けを行うなど、詳細なアプローチが可能となります。
しかしながら、欠点としては、同義語を捉えることができない点が挙げられます。先ほどの例で見てみましょう。「apple computer」ではなく、Apple社が開発した「macintosh」がクエリとして入力された場合、一致するキーワードが存在しません。つまり、3つすべて0点となってしまいます。
それでは、抽出型は同義語に対して全く対応できないのでしょうか。当社においては、当初はユーザー辞書を活用して同義語に対応いたしました。しかしながら、すべての同義語をユーザー辞書に登録することは不可能であるため、このような方式には限界があります。
(2)意味に基づいて探す、セマンティック検索
セマンティック検索は、質問の意味や意図を理解して検索を行う技術です。先述の通り、キーワード検索では同義語への対応に限界がありました。セマンティック検索はこの問題を解決することができます。
今回も、イメージを掴めるように簡単な例を挙げます。意味に基づく検索の動作方法は以下の通りです。
質問のクエリと検索対象をベクトルデータベースに変換し、クエリとの類似度の高さを算出します。

Allganizeでは、言語モデルとしてTransformerのEncoderベースのモデルを使用し、ベクトルデータに変換しました。
このモデルの最大トークン数は512トークンに制限されています。前述の通り、我々はページ単位でチャンク化しているため、少なくとも1K以上のテキストを入力できる必要がありました。
そこで、Longformerや Bigbirdのようなsparse attentionを使用し計算量を削減しトークンが長いモデルも検討しましたが、良いパフォーマンスが得られませんでした。このように、Embedding モデルのトークン数制限やパフォーマンスの限界により課題があり、抽出型モデルでのセマンティック検索の導入は見送っています。
(3)ハイブリッド検索… キーワード検索+意味ベースの検索
ここまでお読みいただき、Allganizeでは類義語に適切に対応できていないのか?と思われたかもしれませんが、そうではありません。
現在、Allganizeではキーワード検索とセマンティック検索を組み合わせたハイブリッド検索を使用しています。
キーワード検索のモデルには、上述したBM25を使用しています。セマンティック検索について、先ほど述べたようなモデルのトークン数に制限がありましたが、最近では性能の良い4k〜8kモデルも公開されています。
Langchain RAGのベースラインとして使用されているOpenAI Embeddingも4kを超えており、nomic-embed-text、bge-m3、gte-large-enモデルはすべて最大トークン数が8192トークンで、パフォーマンスも優れています。
しかし、社内でパフォーマンスを比較したところ、OpenAI Embeddingモデルを単独で使用した場合、パフォーマンスは良好ではありませんでした。そのため、BM25スコア、ドキュメントのタイトルをベクトルに変換してクエリと比較したコサイン類似度スコア、同様にドキュメントのページに対するコサイン類似度スコアを併用しました。
プロセスを簡単に説明します。

上記のように、①キーワード検索とクエリのBM25のスコア、②ドキュメントのタイトルとクエリの類似度のスコア、③ページの内容とクエリの類似度のスコアの合計3つのスコアを算出します。そして3つのスコアを正規化した後、それらを合計して最終スコアを算出し、最も高いスコアを持つ上位 n件をプロンプトに入力します。
このように、Allganizeでは複数のアプローチを適切に組み合わせることで、質問に関連する情報を精度高く探し当てます。
さまざまなケースに対応できる、AllganizeのRetriever最適化戦略
ここでいくつか疑問を持つ方もいらっしゃると思います。
ドキュメントのタイトルが意味のないテキストだった場合、どうなるのでしょうか? ver_1.pdf、最終版.docx といったドキュメント名で文書を作成しているケースも珍しくありません。
また、対象のドキュメントが英語だった場合、ユーザーが日本語で質問したらどうでしょうか?
Allganizeの RAG では、Retriever Optimization(Retrieverの最適化)を することで、上記のようなケースにも対応できます。
例えば、タイトルに意味のないテキストが設定されていた場合、タイトルのベクトルの重みを0に設定することで、スコアに反映されないように制御できます。
2つ目の疑問のケースでは、登録されているドキュメントと質問がそれぞれ英語と日本語であるため、キーワード検索は意味を為さなくなります。ページベクトルの重みを高め、BM25スコアを下げることで、パフォーマンスが向上するでしょう。
このように、状況に応じて RAG のRetrieverを最適化することで、質問と関連性の高い情報を検索したうえでLLMへのプロンプトに追加できるようになり、回答生成精度を向上させることができます。
企業の業種や業務によって利用するドキュメントの形式などは異なるのでは?と疑問を持たれた方、Allganizeではユーザー毎にReterieverの設定を最適化できるようにしていますので、このようなケースでも安心してご利用いただけます。
まとめ
- 企業が生成AI・LLMを利用する際、社内情報・特定情報の活用や、ハルシネーションの低減の観点で、RAGの活用が必要不可欠
- RAGによる回答自動生成においては、検索のRetrieverの精度が非常に重要
- データベースの仕組みや検索の仕組みはさまざまで、それらが回答生成精度のパフォーマンスに大きく影響
- Allganizeでは、ドキュメントの段落、表、チャートに対してパースを行った後、3つの軸「キーワード検索」「タイトル類似性」「ドキュメントの内容の類似性」で質問との関連度を判断。ユーザーに最適化されたRetrieverに基づいて、回答を自動生成できる仕組みを提供
企業の生成AI・LLM活用をオールインワンで簡単に実現する、Allganizeの「Alli LLM App Market」では、上述したRAGの仕組みを標準実装しています。"ドキュメントから回答自動生成"を含む、100個以上の業務用の生成AI・LLMアプリをご提供しています。
ここまで技術的な側面に焦点を当ててお話ししましたが、Alli LLM App MarketでのRAGの利用方法はとても簡単です。ドキュメントデータを連携していただくだけで、すぐに回答を自動生成できるようになります。
Alli LLM App Marketでは、「誰でも簡単に、生成AI・LLMを本格活用できること」を追求していますので、<社内マニュアルからの自動応答>といった、多くの方が実現したいことも、Alli LLM App Marketなら、とても簡単です。
ドキュメントをアップロードするだけでRAGのデータベースができあがり、すぐにRAGの検索対象に含めることができますので、誰でも簡単に実現できます。
Retrieverの最適化も、フィードバック機能をはじめユーザー様ご自身で簡易に実施いただけるようにしており、本記事でご紹介したような複雑な仕組みを意識することなく活用いただけます。
最後に
急速に変化する生成AI・LLMや、RAGソリューションを適切に業務活用されたい場合は、Allganizeがお手伝いいたします。RAGソリューションのデモンストレーションや活用方法をご紹介しておりますので、お問い合わせフォームよりお気軽にご連絡ください。
関連リンク

