■技術解説■ 生成AIのハルシネーションを低減するRAG。図表データまで特定できる"企業向けRAG"とは?(前編)

生成AIのハルシネーションを低減する技術として注目されるRAG(Retrieval Augmented Generation:検索拡張生成)。
このRAG(ラグ)という技術を活用することで、特定ドキュメント等から回答を自動生成できます。
企業向けの生成AIツールを提供している企業でも、RAG機能を前面に打ち出す企業も増えているため、目にしたことのある方も多いかもしれません。
本記事では、RAGの概念、動作の仕組み、RAGにおける検索性能の重要さ、RAGの性能を向上させる戦略について説明します。
1回目の今回は、RAGの概念、仕組み、RAGにおいて重要なポイントについて簡単に解説します。
RAGとは?
RAGの概念
RAGは、2020年5月に発表された論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(知識集約型NLPタスクのための検索拡張生成)」で初めて登場した概念です。
この論文の第一著者であるパトリック・ルイス(Patrick Lewis)博士はMeta社に在籍中にこの論文を執筆し、現在はCohereでLLM(大規模言語モデル)のモデル開発リードを務めています。
RAGは、この論文の中でLLMの持つ課題に対する解決策として提示されました。
論文では、LLMに対する問題定義が明確になされています。
まず、ドメインに特化した知識については限界がある点です。LLMは膨大な一般情報をもとにトレーニングが行われており、一般的な質問に対してはかなり上手に答えることができます。しかし、業界特有の情報など、領域特化の知識については学習できていない場合があり、適切な回答を返せないことがあります。
また、LLMはあらかじめトレーニングした情報をもとに回答するため、その知識は学習当時の情報です。継続的に新しい知識がアップデートされない点も課題として挙げられます。
参考)論文へのリンク
このLLMの問題点に対する代替案は主に2つあります。
1つ目の案は、LLMに対してドメイン特化の情報を追加学習させる方法、つまりファインチューニングです。しかし、このアプローチはコストもかかり、新たな情報に対応させるためには追加学習を繰り返す必要があり、最新情報への迅速な対応が難しいというデメリットがあります。
そして、もう1つの案として提案されたのが、RAGの仕組みです。
LLMが質問に対する回答を生成する際に、回答に必要な情報を外部から検索し、LLMに参考情報として与えることで、追加学習せずともLLMが未学習の情報も含めて回答を生成できるようにします。
この論文では、RAGの実現方法として、パラメータとノンパラメータを組み合わせるアプローチを提案しています。わかりやすく例えるならば、参考図書を持ち込める試験(オープンブック試験)と考えていただければと思います。
オープンブック試験では、既に覚えている内容(=パラメータ)と、参考図書に記載されている情報(=ノンパラメータ)を組み合わせ、解答を作成します。
同じように、RAGも、回答を生成する際に外部のデータベースを参照することで、社内情報や最新情報など、LLMが事前学習していない情報を回答に反映して回答を生成することができるのです。
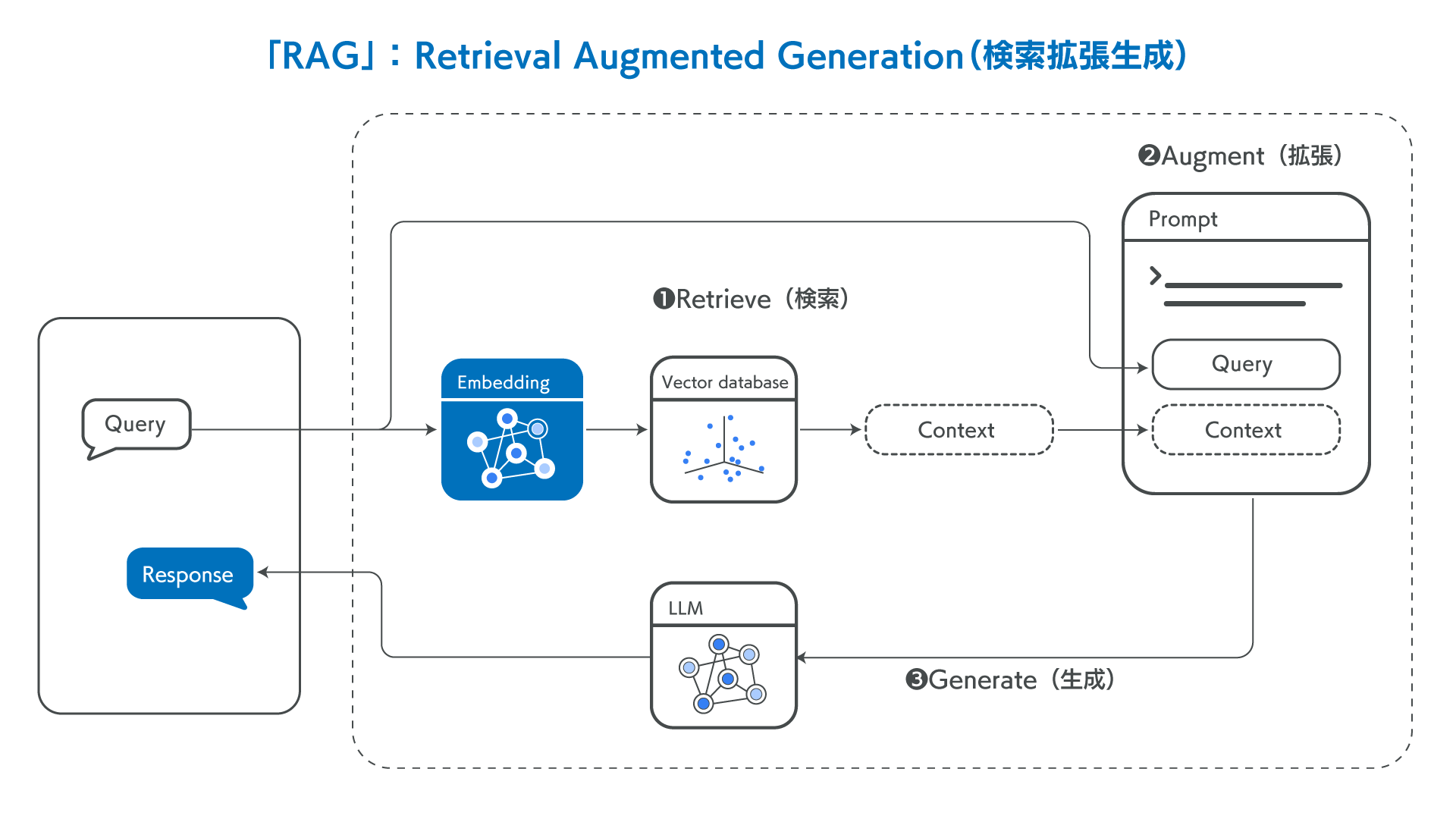
それでは、RAGがどのような流れでどのように回答を生成するのか、簡単にご紹介します。
RAGの仕組み
1. 検索(Retrieve)
質問を入力すると、外部ナレッジから質問に関連する内容をAIが検索します。
ベクトルデータベースから情報を検索し、質問と関連度の高い情報がLLMへ追加情報として与えるコンテキストとして抽出します。
2. 拡張(Augment)
前段の検索(Retrieve)の段階で検索した情報を、ユーザーが入力した質問に追加します。(=拡張)
外部情報が追加されたコンテキストを、プロンプトテンプレートに入力します。
3. 生成(Generate)
最後に、拡張されたプロンプトがLLMに連携され、外部情報も加味した内容で回答が生成されます。
RAGにおいて重要なこと
上記の検索→拡張→生成のステップを見ていただくと、RAGにおいて、検索(Retriver)の精度が重要であることにお気づきになるのではないでしょうか。
質問に関して適切な答えを外部データベースから見つけることができれば、その後の拡張、生成のステップにうまく繋がり、ユーザーが求める回答を返すことができます。
逆を言えば、最初の検索ステップの検索精度が低い場合、適切でない情報を抽出してしまう可能性があります。そうすると、誤った情報をもとにLLMが回答を生成してしまい、最終的に生成される回答内容が期待と異なってしまう恐れがあります。
企業利用に耐えうるRAGとは
企業が実際の業務で使用するドキュメントは、文章量も多く、内容も複雑で、さらに表や図が入るような文書も珍しくありません。
企業向けのRAGにおいては、複雑な表から情報を特定したり、ページ数の多い文書から質問に関連する記述箇所を特定するなど、Retrieverが解決しなければならない要素がたくさんあります。
"RAGを実装している"というソリューションの中には、単純な文書や簡単な質問に対応できるだけ、というものも存在しますので、注意が必要です。
次回の「■技術解説■ 生成AIのハルシネーションを低減するRAG。図表データまで特定できる"企業向けRAG"とは?(後編)」では、表形式のドキュメントに対してRAG性能を高めるためのAllganizeのアプローチをご紹介します。
関連情報




